
 中国におけるサーバのトップメーカーである曙光のブース。手前にあるのは超並列計算機TC4000A。中国科学院計算機研究所の支援を受けて開発され,最大2128個のAMD OpteronプロセッサをMyrinet 2000で接続して10.2TFLOPSのピーク性能を達成する。他にも,デュアルコアのOpteronを8個接続して16-way SMPとしたA950など,先端的なサーバが展示されていた。
中国におけるサーバのトップメーカーである曙光のブース。手前にあるのは超並列計算機TC4000A。中国科学院計算機研究所の支援を受けて開発され,最大2128個のAMD OpteronプロセッサをMyrinet 2000で接続して10.2TFLOPSのピーク性能を達成する。他にも,デュアルコアのOpteronを8個接続して16-way SMPとしたA950など,先端的なサーバが展示されていた。
1. 学会の概要
本会議はIEEE主催で1年半に1回開かれるハイパフォーマンスコンピューティング関係の国際会議である。昨年の大宮に引き続き,今年は北京で開催された。私は1995年の台北での第1回会議に参加して以来,10年ぶりに参加した。今回は,アーキテクチャ関係,グリッド関係,応用関係の発表が多く,私の研究テーマである行列計算アルゴリズム関係の発表は多くなかった。しかし,基調講演が充実しており,TOP500の最新結果に関するDongarra教授の講演,再構成可能なハードウェア上での高性能計算に関するPrasanna教授の講演など,興味深い発表をいくつか聞くことができた。また,ハードウェアメーカーなど各社がブースを設けて製品を展示しており,中には中国のサーバメーカーである曙光のブースなど,なかなか見る機会がない展示もあった。
2. 興味深かった講演
特に興味深かった発表について,以下にまとめる。なお,本会議の会議録はIEEE Computer Societyより刊行されている。
(1) An Overview of High Performance Computing
Jack. Dongarra(Univ. of Tennessee)
スーパーコンピュータのベンチマークであるTOP 500の最新結果の紹介と,そこから予想される将来の技術動向,技術課題が述べられた。まず,11月に発表された最新のTOP500の1位はLawrence Livermore National LaboratoryのIBM Blue Gene。131,072個と極めて多数のプロセッサを搭載する超並列計算機だが,LINPACKでピークの75%以上と,驚異的な高効率を達成している。また,動作周波数を700MHzに抑えることにより,1位〜25位に入った他の計算機に比べ,消費電力1Wあたりで8倍以上の高い性能を実現している。
一方,500位までの結果から読み取れる傾向として,プロセッサもネットワークも標準品を使った並列計算機の割合が激増している。以前はプロセッサもネットワークも独自開発が多く,その後はネットワークのみ独自開発の製品が多かったが,このコモディティ化が一段と加速している。使われているプロセッサは2/3がintel製で,IBM製,AMD製が続き,この3社で91%を占めている。また,用途としては学術用・研究用の割合が低下して産業用が増加し,性能で見た割合では全体の51%を占める。国別では,1位の米国の割合が増え続け,2位の日本は大きく低下している。中国は3位だが,GDPあたりのFLOPS値では日本を抜いている。
今後の予想としては,プロセッサのマルチコア化が進み,2010年代末には256プロセッサを集積したチップが登場する。また,プロセッサとメモリの速度の乖離が続く。現在までのデータを外挿すると,2020年にはメモリの相対スループットを表すByte/Flopが0.008word/flopまで低下し,メモリのレイテンシは,データが演算器に到着するまでに数万回の浮動小数点演算ができるほど大きくなる。また,プロセッサの増大に伴い,MTBFが今以上に短くなる。このような課題に対処するための方策として,主メモリの低いスループット/高いレイテンシを許容できる新アルゴリズムの開発,データ参照の局所化をプログラマが意識できるような言語の開発,ハードウェアに備わっている耐故障性を活用できるMPIの開発,性能とソフトウェアの可搬性を両立するための自動チューニング手法の開発などが重要項目として挙げられた。
(2) Supercomputing on Reconfigurable Platforms
Viktor Prasanna(Univ. of South California)
FPGAを利用することで汎用プロセッサよりも高速な性能を実現できる例として,BLAS専用のプロセッサ,および疎行列の行列ベクトル積専用のプロセッサを設計した事例が述べられた。FPGAでは,チップ上の論理素子を使って様々な演算器を自由に設計でき,演算器の個数やパイプライン段数も自由に決定できる。論理素子を使ってキャッシュメモリを構成することもでき,また,外部メモリとのインタフェースも柔軟に変更できる。このような自由度がある反面,演算器を多く取るとキャッシュメモリに使える素子数が少なくなること,回路を複雑化するとクロック周波数を大きくできなくなることなどのトレードオフが存在する。本研究では,各ノードにFGPAが搭載された計算機であるCray XD1を用い,これらのトレードオフの下で密行列・疎行列の基本演算を行う専用プロセッサの最適設計を行った。その結果,密行列の乗算の場合で,汎用プロセッサであるPentium 4の5〜9倍の性能を実現した。また,消費電力1Wあたりの性能では,12〜22倍と高い値を実現した。一方,疎行列ベクトル積においても,対象とする疎行列の構造に応じてFPGAの構成を組み替えることで演算性能を向上させ,Pentium 4の最大20倍の性能を実現できた。
(3) Adaptive Strassen and ATLAS's DGEMM: A Fast Square-Matrix Multiply for Modern High-Performance Systems
Paolo D’Alberto (Carnegie Mellon University) and Alexandru Nicolau (Univ. of California, Irvine)
Strassenのアルゴリズムは,行列の再帰的な分割を行うことで,行列乗算の演算量をO(n^3)からO(n^2.86)に削減できる。しかしこのアルゴリズムでは,多数の小行列の加減算が必要となるため,主メモリとプロセッサ間のデータ転送量が大幅に増加する。そのため,階層的なメモリを持つ計算機では,再帰的な分割を途中で止めたほうが良い性能が得られることが知られている。また,最適な再帰分割の段数は,対象とする計算機と行列サイズnによって異なる。そこで本研究では,プログラムのインストール時に行列乗算の性能αと行列加算の性能πを測定し,それに基づいて最適な段数を決める方式を開発した。Alpha ev67,Itanium 2,SPARC64など多数のプロセッサ上で評価した結果,本方式はATLAS単体に比べて最大30%の高速化を達成できた。
感想: 本発表は行列計算の自動チューニングに関する発表であり,(i) まずプログラムの構成要素に対する性能を実測し,(ii) それをもとにモデルを用いてプログラム全体の性能を予測する,という階層的な性能予測手法を用いている。この点で今回の私の発表と同じアプローチを取っており,興味深かった。しかし,実験結果を見ると,最適な段数の予測値(グラフ中のS-adaptive)と実測して得られた最適値とが異なっている場合がかなり多い。これは,1000×1000の行列で測定したαとπのみから予測値を決めているためと思われる。実際にはαとπは(論文中でも述べられている通り)行列サイズの関数である。したがって,複数の行列サイズに対して実測を行い,補間によって関数α(n),π(n)を求めてから,それをモデルに代入するというアプローチを取れば,予測精度はもっと向上すると思われる。
(4) Fracture Analysis Using Reconfigurable Computing Systems
A. P. Kumbhar (Hardware Technology Development Group, India) 他7名
構造物の亀裂発生メカニズムに対する有限要素法解析を,FPGAを用いて高速化した。有限要素法では,計算時間の大部分がコレスキー分解による連立一次方程式の求解に費やされるため,この部分をFPGA化の対象としている。用いるFPGAボードはHardware Technology Development Group社で開発されたものであり,Xilinx社製XC2V3000(300万ゲートのFPGA)を2個搭載し,64ビット,66MHzのPCIバスに接続される。また,ボード上に256MBのDRAMと4MBのキャッシュを搭載している。FPGAの容量の制約のため,コレスキー分解時にはそれ専用のロジックをダウンロードし,前進後退代入時にはそれ専用のロジックをダウンロードし直す。コレスキー分解のロジックは,内積形式をベースとしており,一度に4列×64行のデータをメモリからチップ上のバッファに取ってきて,4個の乗加算器により64行分の内積演算を行う。また,対角要素の平方根の逆数をかける部分も,ハードウェアとして実装している。FPGAは,100MHzのクロック周波数で動作する。このボードを使って1000元の行列のコレスキー分解を行ったところ,3.6GHzのXeonに比べて11.6倍,1.8GHzのOpteronに比べて6.9倍の加速が得られた。
感想: コレスキー分解および前進後退代入という比較的複雑な演算に対してFPGAによる実装を行った研究であり,非常に興味深かった。しかし,乗加算器4個で100MHzということは,高々800MFLOPSの性能であり,最新のマイクロプロセッサと比べると高性能とは言えない。XeonやOpteronに比べて高速という結果が出ているのは,後者で使ったコードが最適化されていないためと考えられる。また,(a) 本来疎行列である有限要素法の行列を密行列として扱っている,(b) コレスキー分解では,ブロック化により性能向上を図るのが普通であるが,本研究では列方向(i方向)のループ展開しか行っていない,(c) 扱える行列が1000元までに限定されている,などの問題点があり,実用化まではまだ距離があるように感じた。上記2の講演では,演算器とキャッシュ間の資源配分の最適化が重要だと指摘されていたので,それも考慮して最適設計をすると面白いと思った。
(5) LAPACK in SILC: Use of a Flexible Application Framework for Matrix Computation Libraries
Tamito Kajiyama, Akira Nukada (Univ. of Tokyo), Hidehiko Hasegawa (Univ. of Tsukuba), Reiji Suda and Akira Nishida (Univ. of Tokyo)
行列計算ライブラリは,高性能を追求するため,各計算機上で様々なライブラリが提供されている。しかしインタフェースはライブラリ毎に異なるため,プログラム中でライブラリルーチンを直接コールすると,プログラムの可搬性が損なわれてしまう。そこで本研究では,ソースレベルでライブラリへの非依存性を実現するSILCというフレームワークを提案した。SILCでは,ユーザプログラム上で行列,ベクトルなどをオブジェクトとして定義し,これらに対する演算を,数式風に記述できる。また,ライブラリルーチンの実行に必要な配列は,SILCの側で確保する。これにより,プログラムを変更することなく,多種類の環境で多種類のライブラリに接続することが可能となる。今回は,ユーザプログラムとライブラリが同一の(逐次型)計算機上で動作する場合,および前者が1台の計算機,後者がSMP上で動作する場合を対象として実装を行った。CRS形式の行列に対して,右辺ベクトルの異なる複数の問題を解く場合,行列格納形式の変換プログラムをユーザが書かないとすると,CRS形式の入力を受け付けるCG法ソルバを複数回コールして解かざるを得ない。一方,SILCを用いると,自動的に格納形式の変換を行い,右辺ベクトルが複数の場合を得意とするLAPACKのルーチンをコールしてくれる。評価を行った結果,右辺の本数が多い場合は,SILCを用いたほうが高速化されることがわかった。
感想: DongarraらのSANS(Self-Adapting Numerical Software)をはじめとして,問題に応じて最適な求解ルーチンを自動選択してくれるシステムが最近注目されているが,本研究はそのためのベースになると思う。今回の発表では,ユーザプログラムが単体の計算機,ライブラリ側がSMPという構成までだったが,将来は,後者あるいは両者が分散メモリ型並列計算機の場合にまで拡張されるとのことである。こうなると,プロセッサ台数,データ分割方式,データ通信方式など,最適化すべきパラメータが飛躍的に増える。今までの自動チューニングの成果が生かされるとともに,自動チューニング研究に対しても新たな課題を与えてくれることを期待したい。なお,SILCのオーバーヘッドの大きさがわかるような性能評価結果があると,ユーザにとってより有用な情報になったと思う。
(6) Reduction Transformations for Optimization Parameter Selection
Y. Che, Z. Wang and X. Li (National Lab for parallel and Distributed Processing, China)
科学技術計算プログラムの性能は,ブロッキングのサイズやアンローリングの段数など,多くの性能パラメータに依存する。したがって,性能を最適化するには,これらのパラメータの最適値を求めることが不可欠である。最適値を求める方法は,プログラムの静的な解析による方法とプログラムを実際に実行して最速となるパラメータを求める方法の2つに大別されるが,前者では精度の良い決定が困難,後者では膨大な実行時間が必要という問題点がある。本研究では,パラメータの値を変えたときのプログラムの実行時間の比を保ったまま,絶対的な実行時間を大きく減少させるようなプログラムの変換(意味論的に等価なプログラムへの変換ではない)を Reduction Transformation と呼び,その例として時間ステップに関する最外側ループの回数削減,多重ループの外側ループの回数削減などを挙げた。そして,これらの変換を行列乗算や SPEC ベンチマークに適用することにより,実際に実行時間比を変えずに絶対的な実行時間を数十分の1に削減し,パラメータ最適化のコストを大きく削減できることを示した。
感想: 本研究で提案している手法は,プログラムの最適化を人手で行う場合にはよく使われる手法であり,本研究ではこれをコンパイラにより自動的に行うことを目的としていると思われる。コンパイラ技術の現状について知識がないため,本研究の水準がどの程度かはわからなかったが,自動チューニングの研究と比較すると,最適パラメータの決定という同じ問題に対し,プログラムの部分実行という同じアイディアを使って取り組んでいる点が興味深かった。
(7) 3-D Seismic Imaging using High-Performance Parallel Direct Solver for Large-Scale Finite Element Analysis
J. H. Kim (KISTI, Korea), D. Yang and C. Shin (Seoul National University)
地震波の解析から石油や天然ガスの貯蔵量を推定するには,3次元の地震波解析が必要となる。この問題を有限要素法で定式化し,SWEET と呼ばれるアルゴリズムを用いると,複数の右辺を持つ連立一次方程式 AX = B の解を求める問題となる。本研究ではこの問題に対し,Domain-wise Multifrontal Solver [1][2] と呼ばれる直接法ソルバを用いて求解を行った。Domain-wise Multifrontal Solver は,マルチフロンタル法の一種で,解析領域を複数の部分領域に分割し,各部分領域をさらに境界節点と内部節点に分けて,内部節点に対応する変数を消去し,外部節点だけの方程式を作成する。次に,2つの部分領域を併合し,新しく内部節点となった節点に対応する変数を消去する。この操作を再帰的に続け,変数の消去を行っていく。また,内部変数の消去(Schur complement の作成)では,計算対象の行列を密行列と見なし,最適化された LAPACK を使用する。数値実験の結果によると,このアルゴリズムに基づくソルバは,WSSMP や MUMPS など,高度な最適化がされたスパースソルバと同等以上の性能を達成できる。また,巨大問題向けに外部記憶を利用するアウトオブコアソルバの作成も比較的容易だという。本報告では,100×100×100 のメッシュに対する方程式を 256 個の Xeon 2.8GHz からなるクラスタで 470GFLOPS の性能で解いた例,181×171×201 のメッシュに対する方程式を 128CPU の IBM p690 で解いた例が示された。これらはスパース直接法で解かれた問題としては,最大規模である。
参考文献
[1] J. H. Kim and S. J. Kin: A Multifrontal Solver Combined with Graph Partitioners, AIAA journal, Vol. 38, No. 8, pp. 964-970 (1999).
[2] S. J. Kim et al., IPSAP: A High-Performance Parallel Finite Element Code for Large-scale Structural Analysis Based on Domain-wise Multifrontal Technique, Proceedings of the IEEE/ACM SC2003 Conference.
感想: 600万元という超大規模の連立一次方程式をスパース直接法で解いて地震波解析の結果を出しており,大変迫力のある論文だった。本研究で用いている Domain-wise Multifrontal Solver は,SC2003 で Gordon-Bell 賞を受賞しており,スパース直接法の分野でも重要な進展だと思われる。原論文を読んでみたい。
3. 写真
中国におけるサーバのトップメーカーである曙光のブース。手前にあるのは超並列計算機TC4000A。中国科学院計算機研究所の支援を受けて開発され,最大2128個のAMD OpteronプロセッサをMyrinet 2000で接続して10.2TFLOPSのピーク性能を達成する。他にも,デュアルコアのOpteronを8個接続して16-way SMPとしたA950など,先端的なサーバが展示されていた。

 IBMのブース。スーパーコンピュータのTOP500で1位となったBlue Gene(藍色基因)を展示していた。700MHzで動作するデュアルコアのPowerPC 440プロセッサを131,072個搭載するシステム(最近Lawrence Livermore National Laboratoryに設置完了)では,360TFLOPSのピーク性能(LINPACK benchmarkでは280TFLOPS)を達成する。ソフトウェアとしては,Blue Gene用に最適化されたXL Fortran,C,C++,MPI,ESSLなどが用意されている。
IBMのブース。スーパーコンピュータのTOP500で1位となったBlue Gene(藍色基因)を展示していた。700MHzで動作するデュアルコアのPowerPC 440プロセッサを131,072個搭載するシステム(最近Lawrence Livermore National Laboratoryに設置完了)では,360TFLOPSのピーク性能(LINPACK benchmarkでは280TFLOPS)を達成する。ソフトウェアとしては,Blue Gene用に最適化されたXL Fortran,C,C++,MPI,ESSLなどが用意されている。
 マイクロソフトのブース。Windowsをベースとして簡単にクラスタを構築できるWindows Compute Cluster Server 2003のデモを行っていた。インストールがリモートで行えたり,計算ノードの追加がGUIで行えるなど,Linuxベースの構築に比べて構築が格段に容易とのこと。ただし,クラスタの全ノードにWindows Compute Cluster server 2003をインストールする必要があり,64ビットCPUにしか対応していないなどの条件があり,研究室にあるWindowsマシンを組み合わせて簡単にクラスタを構成するといった用途には向かない。
マイクロソフトのブース。Windowsをベースとして簡単にクラスタを構築できるWindows Compute Cluster Server 2003のデモを行っていた。インストールがリモートで行えたり,計算ノードの追加がGUIで行えるなど,Linuxベースの構築に比べて構築が格段に容易とのこと。ただし,クラスタの全ノードにWindows Compute Cluster server 2003をインストールする必要があり,64ビットCPUにしか対応していないなどの条件があり,研究室にあるWindowsマシンを組み合わせて簡単にクラスタを構成するといった用途には向かない。
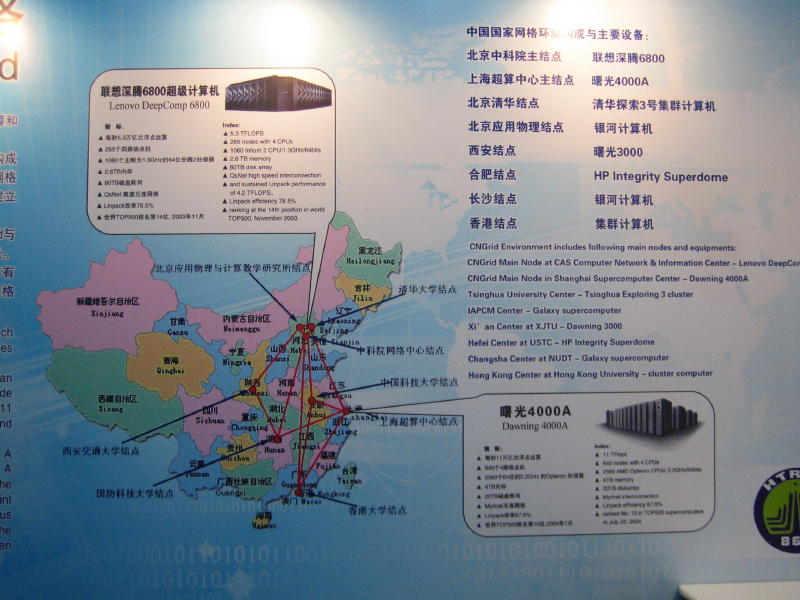 中国の国家グリッドのブース。上海にある曙光4000A(11TFLOPS),北京にある Lenovo DeepComp 6800(5.3TFLOPS)などの計算機が高速ネットワークで結ばれている。
中国の国家グリッドのブース。上海にある曙光4000A(11TFLOPS),北京にある Lenovo DeepComp 6800(5.3TFLOPS)などの計算機が高速ネットワークで結ばれている。

 北京の繁華街である王府井にあった地下の飲食店街。20件ほどの店の屋台風の店が並び,点心,麺類をはじめ様々な軽食が売られていた。全部実物が並んでいるので,名前がわからなくても注文できてとても便利。
北京の繁華街である王府井にあった地下の飲食店街。20件ほどの店の屋台風の店が並び,点心,麺類をはじめ様々な軽食が売られていた。全部実物が並んでいるので,名前がわからなくても注文できてとても便利。
 北京郊外にある頤和園(いわ園)にて。頤和園は西太后が避暑地として造らせた広大な別荘で,世界遺産に登録されている。写真は園内の昆明湖に浮かぶ石舟。
北京郊外にある頤和園(いわ園)にて。頤和園は西太后が避暑地として造らせた広大な別荘で,世界遺産に登録されている。写真は園内の昆明湖に浮かぶ石舟。
 王府井の串焼き屋台にて。サソリ,臭豆腐,タツノオトシゴなど,様々な食材を串焼きにして食べるのは知っていたが,ヒトデまであったのには驚いた。
王府井の串焼き屋台にて。サソリ,臭豆腐,タツノオトシゴなど,様々な食材を串焼きにして食べるのは知っていたが,ヒトデまであったのには驚いた。
学会出張報告のページに戻る
Topに戻る